Static prompts that do not learn
A prompt written today does not know what your senior recruiter approved yesterday. The model never improves at scoring against your actual hiring bar.
The market is full of AI-powered ATS systems with rigid prompts and no learning feedback. You write the prompt once. The system applies it forever. The model never gets smarter about your role, company, or definition of a good candidate.
Worse, many of these tools are keyword matchers with an LLM glued on top. A single LLM talking to itself can only argue for its own conclusion. Weak assumptions and missed signals stay hidden.
A global workforce platform in the EOR and contractor-management space wanted to evaluate what a different approach could look like. We built TalentIQ as a working system to show responsible multi-agent screening: auditable reasoning, measured bias, structured criticism, and continuous learning from recruiter feedback.
Candidate screening at scale has four failure modes that compound. Static prompts do not learn. Single-perspective reasoning misses counterarguments. Opaque outputs are hard to defend. Bias risk needs measurement, not reassurance.
A prompt written today does not know what your senior recruiter approved yesterday. The model never improves at scoring against your actual hiring bar.
A system that only argues for its own conclusion hides its own weaknesses. Errors a human review panel would catch slip through.
Most AI screening tools output a number with no usable explanation. Recruiters do not trust it, and auditors cannot review it.
Pattern-matching on names, schools, employment gaps, or geography can leak demographic proxies if you are not measuring carefully.
TalentIQ is built on Microsoft AutoGen and structured as four sequential layers of agent activity. Each layer has a distinct purpose, and each layer's output is challenged by the next.
This is a deliberate departure from one-agent, one-decision patterns. Structuring screening as a panel with built-in adversarial review lets the system catch reasoning errors that single-pass systems miss.
Parser Agent extracts and normalises candidate signals from the CV: skills, experience, education, and structured metadata. It produces a canonical candidate profile that downstream agents work from, so every later agent reasons over the same shared representation.
A panel of independent evaluators scores the candidate across distinct dimensions. Each evaluator works in isolation so its reasoning is not contaminated by the others.
Specialised agents take adversarial stances against the Layer 2 outputs. The system stress-tests conclusions through AutoGen group chat. Every disagreement references specific upstream reasoning.
Synthesiser Agent composes the final score and reasoning trace, integrating evaluator outputs and panel critiques. Learning Agent observes recruiter overrides and updates company-specific rule memory for future evaluations.
Layer 3 is where the system stress-tests its own conclusions. The panel runs as a structured conversation through AutoGen group-chat patterns. It is not a free-for-all.
Each agent's output references specific upstream reasoning. Every disagreement is logged, and dissent is preserved for recruiter and auditor review.
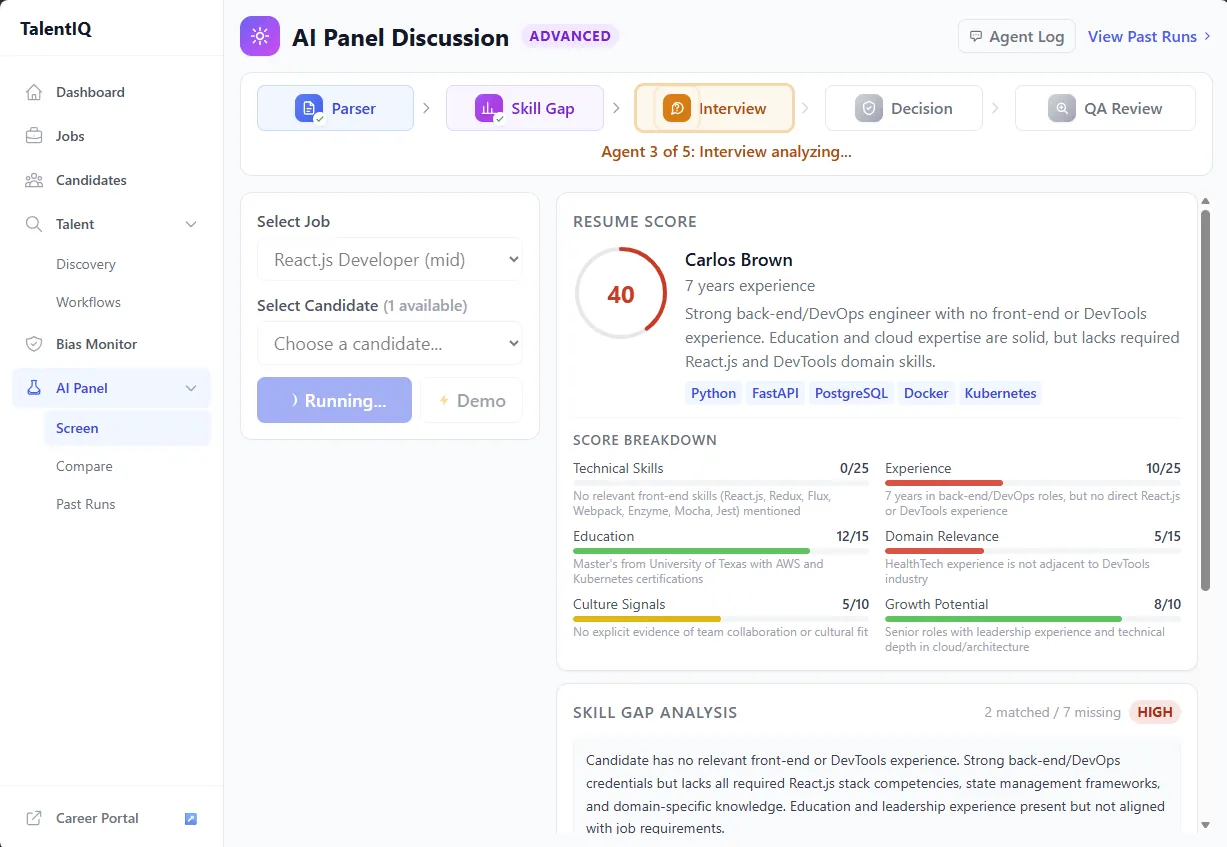
This screen supports the adversarial review story directly: staged agent analysis, structured scoring, and a visible reasoning surface before a recruiter sees the result.
Scores skills and experience against role requirements, with explicit reasoning per requirement.
Evaluates whether the candidate career stage and trajectory fit the role seniority and growth profile.
Runs counterfactual rewrites of the CV by swapping name, school, and geography signals. Flags score deltas above threshold.
Challenges the reasoning of evaluation agents. Looks for weak reasoning, unjustified weighting, and conclusions that do not follow from the evidence.
Argues the opposite conclusion to whatever Layer 2 produced. The goal is to force the strongest possible case for the alternative.
Surfaces failure modes and red flags the evaluators may have missed or under-weighted: thin claims and role-fit assumptions that do not hold up.
Argues the strongest possible case for the candidate, ensuring weaker or non-obvious signals are not dismissed prematurely.
The Synthesiser integrates evaluations and critique into the final recommendation. The Learning Agent observes feedback and updates company-specific rule memory.
Recruiters see not just the final score, but the strongest arguments against it. Dissent from the panel remains in the audit trail.
The Learning Agent distils recruiter overrides into memory that Layer 2 and Layer 3 agents consult on future evaluations.
One mid-senior backend engineering candidate from the test batches showed why the panel layer mattered.
The Role-Match and Stage-Fit agents initially under-scored the candidate. The CV listed modest titles (Senior Engineer, no formal lead designation), and Stage-Fit flagged the trajectory as a stretch for the target role.
The Steelman Agent surfaced three concrete signals the evaluators had under-weighted: ownership of a payments service running production traffic across two regions, mentoring responsibility for two junior ICs, and recurring ownership of incident postmortems.
The Counter-Challenge Agent pressure-tested whether postmortem ownership was true leadership or just on-call rotation. The Synthesiser weighed both arguments, raised the final score, and preserved both reasoning lines in the audit trail.
The recruiter decision matched the upgraded recommendation. This is the exact failure mode static-prompt ATS systems create at scale: strong candidates filtered out on title-string matching.
The panel discussion, adversarial review, and synthesis kept the candidate's signal visible past title-string matching.
The first version was not perfect. The system had to be tuned like a real review panel, not a static prompt chain.
Three of the four Layer 3 agents were oriented toward challenge, with only the Steelman defending the candidate. The Synthesiser consistently pulled scores down, and false negatives climbed in the early cohort.
Unconstrained AutoGen group chat ran long because agents kept finding new things to argue about, and per-candidate cost climbed with it.
Unlike stateless prompt-and-response systems, TalentIQ agents maintain memory across evaluations. Memory includes the company's hiring history, recruiter feedback patterns, role-specific rules accumulated over time, and each agent's own past reasoning on similar candidates.
Memory is scoped per company. What one client's agents learn never leaks to another.
Recruiters can override scores with reasons. The Learning Agent observes overrides and updates company-specific rule memory.
The system can learn that a client values open-source contributions more than the default rubric suggests, or penalises employment gaps less than the default.
Across test batches, the gap between agent scores and recruiter overrides narrowed as override patterns accumulated in memory.
Configuration controls what each agent is allowed to use as a signal. These choices are visible in the audit trail per decision, so recruiters and auditors can see exactly what the system was permitted to consider.
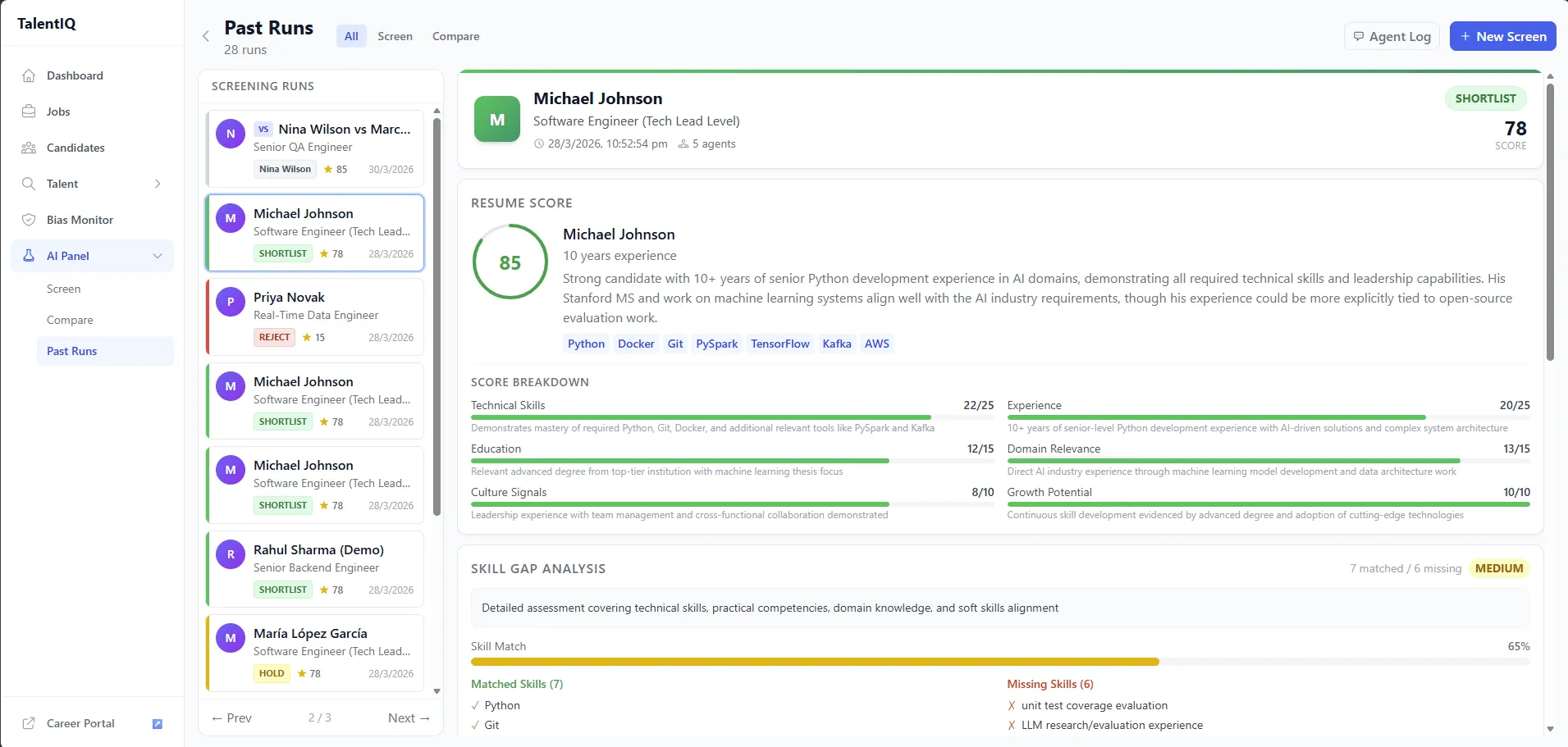
This review screen shows the level of transparency the system was designed for: scored dimensions, skill-match evidence, outcome state, and agent-attributed review history.
Single-prompt systems cannot separate concerns cleanly. Multi-agent architecture gives each agent a clear responsibility, a testable boundary, and an interpretable contribution to the final decision.
A system that only argues for its own conclusion hides its weaknesses. The panel discussion layer forces every decision to survive structured criticism before it reaches the recruiter.
AutoGen handles agent communication, group-chat patterns, and role definitions out of the box. That let the team focus on the screening domain rather than reinventing orchestration.
A screening system that does not learn from recruiter feedback cannot get better at scoring against a specific hiring bar. Per-company memory means every override compounds.
Most AI fairness tooling is bolted on after the fact. TalentIQ made the auditor a peer agent in Layer 2, so every scored candidate is audited.
TalentIQ showed that layered multi-agent screening can produce recommendations that have already gone through adversarial review before a recruiter sees them.
The system adapts to a company's hiring standards through recruiter feedback while remaining auditable and bias-aware.
The panel discussion layer surfaced gaps in Layer 2 evaluator reasoning that single-pass systems would have missed entirely.
The Counter-Challenge Agent moved the Synthesiser's score in enough cases to show that adversarial review was affecting outcomes.
The Steelman Agent rescued candidates Layer 2 had under-weighted on surface signals, including the under-titled backend engineer.
The bias auditor caught counterfactual score drift on early prototypes that would not have been visible without inline auditing.
The gap between agent scores and recruiter overrides narrowed across batches as the Learning Agent absorbed override patterns.
The evaluating platform team received a baseline for what responsible, learning-based, adversarial AI screening would need to show compliance teams or external auditors.