Jurisdiction matters
A contractor in Germany needs different paperwork than one in Brazil, which differs again from Vietnam. Generic LLM output is wrong here. You need ground-truth jurisdiction data feeding the model.
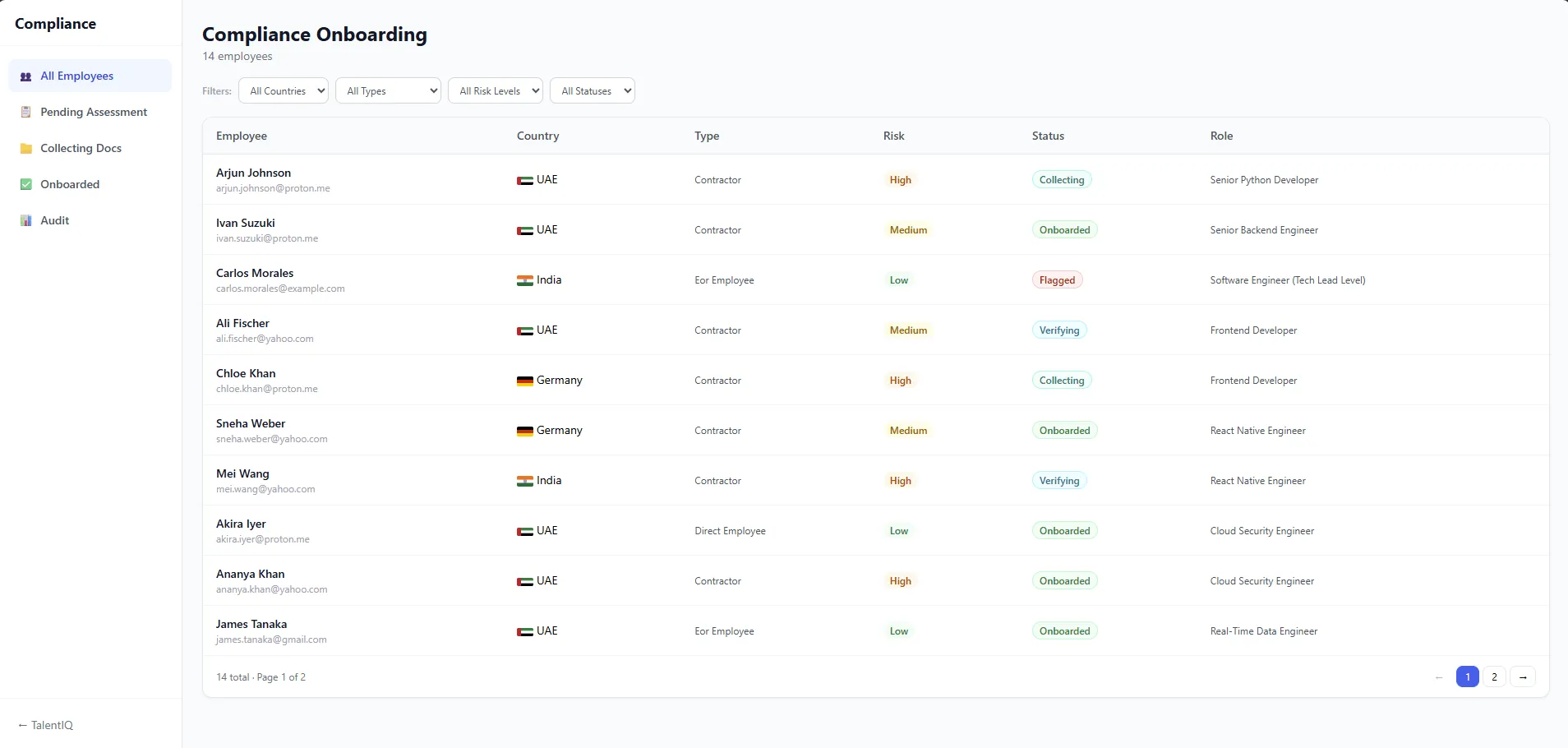
A global workforce platform in the EOR and contractor-management space was evaluating whether AI could meaningfully reduce manual effort in compliance onboarding for international hires.
Onboarding a contractor in a new country involves jurisdiction-specific tax forms, work eligibility checks, contract templates, and varying e-signature regulations.
The existing process required compliance specialists to manually assemble and review the right document set per country, per hire.
They wanted a working system to evaluate whether the current generation of LLMs and RAG systems could handle this complexity reliably enough to be production-bound.
We built that system as a working demonstration that exercised the full architecture end-to-end. Not a slide deck. Not a chatbot wrapped around an LLM.
Compliance onboarding is harder than most AI demos pretend. Generic LLM output is not enough when jurisdiction, sequencing, legal exposure, and vendor flows all matter.
A contractor in Germany needs different paperwork than one in Brazil, which differs again from Vietnam. Generic LLM output is wrong here. You need ground-truth jurisdiction data feeding the model.
Some checks gate others. You cannot issue a contract before tax classification is settled. Signatures cannot be requested before identity verification.
A wrong tax classification or a missed compliance step creates legal exposure for the platform. Not inconvenience. Legal exposure.
During an evaluation, the customer needs to see a real e-signature flow without paying for a vendor account on day one. The architecture has to support both real and mockable integrations.
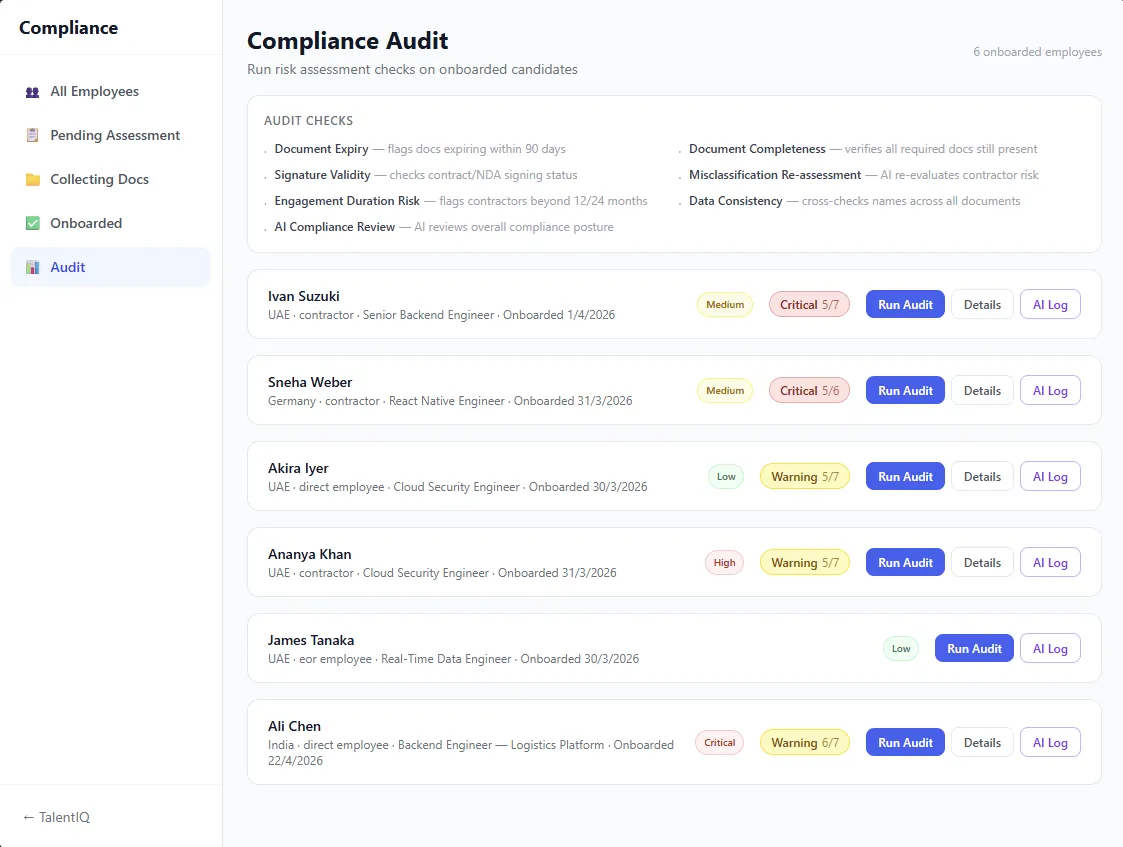
We built an 8-stage gated onboarding pipeline. Each stage has clear entry conditions, an AI-augmented or rule-based execution step, and an exit gate that either advances the candidate or routes to human review.
The architecture had to prove production viability: RAG-backed jurisdiction data, calibrated uncertainty, switchable integrations, citation validation, persisted audit trails, and downstream handoff.
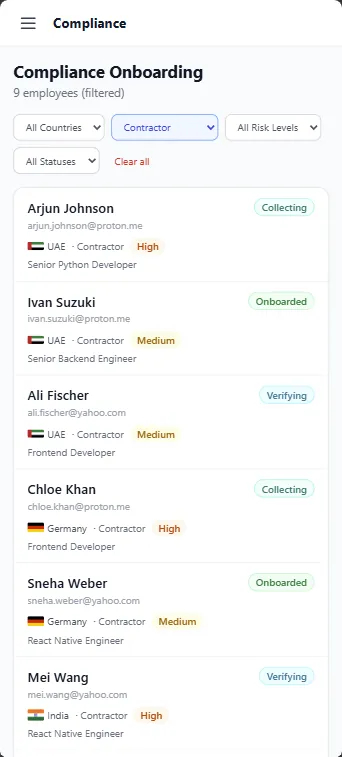
Captures destination country, contract type, and role. The pipeline hard-stops when the country or contract path is unsupported.
RAG-based lookup over jurisdiction-specific compliance documents. Returns the active document set, tax-classification rules, and e-signature requirements. Country profiles are maintained as separate vector collections, so updates to one country do not affect retrieval quality for another.
LLM-driven classification of the contractor against country rules, with explicit reasoning trace and confidence score. Below threshold, the case routes to human review.
Generates the country-specific document pack from templates populated with contractor data. Templates are versioned per country and per regulation date.
Pluggable integration with a mock provider for evaluation and a real provider plug-in path for production.
Switchable between mock provider and real e-signature integration through a single internal interface, so vendor swapping does not require pipeline changes.
Each stage's inputs, outputs, retrieval sources, model decisions, and gate outcomes are persisted as a queryable audit record. That audit record makes the demo reviewable as a regulated workflow.
Completed onboarding payload is published to a downstream system. In the demo, this was a mock HRIS endpoint.
A useful case from the demo cohort: onboarding a Vietnam-based contractor for a part-time technical advisory role. Under Vietnamese tax rules, the role sat between independent contractor and consultant with employee-like attributes — an ambiguous zone.
Stage 2 retrieved Vietnam tax classification rules, contract template set, and e-signature requirements from the country compliance profile.
Stage 3 produced a confidence score below the auto-advance threshold because the role had a fixed monthly retainer and defined working hours, but no exclusivity clause and no employer-provided equipment.
The system produced the correct outcome: not a confident wrong answer, but a flag for uncertainty with a reasoning trace pointing to the clauses that pulled classification in opposite directions.
The compliance specialist confirmed contractor classification, added a note, and the pipeline resumed at Stage 4 with the human decision recorded in the audit trail.
Across the demo cohort, roughly one in four Stage 3 cases routed to human review. The compliance team flagged that ratio as the right shape: high enough to catch ambiguity, low enough to automate the clear cases.
The first version of Stage 3 produced reasoning traces that occasionally cited authoritative-sounding regulatory references that did not exist in the retrieved context. The model knew the shape of a tax-rule citation and generated something plausible when the retrieved documents did not contain a precise match. For a compliance system, this is the worst possible failure mode: confidently wrong output that looks audit-ready. Two changes fixed it. First, the reasoning template was constrained to cite only from retrieved chunks, with citation IDs that mapped back to specific document spans. Second, a post-generation validation step rejected any output whose citations did not resolve cleanly against the retrieval set. Failed validations dropped the case to human review with a flag, instead of letting it pass. After those changes, citation-validation failure rate fell sharply across the test runs and stayed there.
The other early issue was retrieval ranking on countries with overlapping legal vocabulary. Even with per-country collections, edge-case queries could surface high-similarity but wrong-context chunks within a single country's collection. For example, employee tax rules were retrieved for a contractor query when the contractor framing was implicit. We tightened the retrieval prompts and added a query-rewriting step that made the contractor-vs-employee framing explicit before retrieval. Stage 3 confidence stabilised after that.
Country compliance rules change. Fine-tuning would mean retraining. RAG means updating documents. For a domain that changes faster than model release cycles, RAG was the right choice.
Multi-step agent loops are unreliable for compliance work. A gated pipeline with explicit hand-offs is auditable and debuggable. When something fails, you know which stage and why.
Most evaluations get blocked by vendor procurement timelines. Building this switch in from day one let the platform team evaluate the system end-to-end before signing vendor contracts.
For regulated decisions, reasoning that cites unverifiable sources is worse than no reasoning at all. Validating every citation against the retrieval set before accepting output meant the audit trail could be trusted, not just spot-checked.
The system showed that AI-augmented compliance onboarding is technically feasible at a production-quality bar when the LLM is treated as one component, not the whole system.
The gated pipeline, RAG-backed jurisdiction data, citation-validated reasoning, and explicit audit trail gave the evaluating team confidence that the approach could meet their compliance bar.
The architectural patterns from this build now inform how we approach AI workflows that touch regulated processes.
Every stage had explicit entry conditions, execution logic, and exit gates.
Country profiles were isolated so updates to one jurisdiction did not degrade another.
Mock and real identity/e-signature providers shared the same internal interface.
Accepted reasoning had to cite retrieved chunks that resolved cleanly against the retrieval set.
Inputs, outputs, retrieval sources, model decisions, and gate outcomes were queryable per onboarding run.
The same patterns now inform AI workflows that touch compliance-sensitive processes.